Predicting house prices accurately means moving large datasets through reproducible, automated ML pipelines. Ad-hoc notebook runs alone do not scale for production-style delivery or governance.
Approach
Using a real Kaggle house-prices dataset, the project implements an end-to-end ML pipeline on AWS:
- Amazon SageMaker Jupyter notebooks for exploration and model training
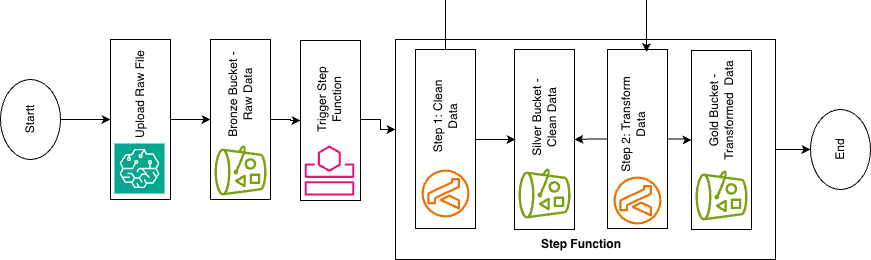
- AWS Lambda and AWS Step Functions to orchestrate data movement and processing
- Amazon EventBridge for event-driven and scheduled triggers
- AWS IAM for least-privilege, role-based access across services
- Amazon S3 for layered storage (medallion-style bronze / silver / gold)
- Amazon CloudWatch for observability
- Amazon RDS where relational storage fits the workflow
- Python for transformation and ML code
Pipeline outputs feed Power BI dashboards so stakeholders can explore price predictions, feature importance, and market trends interactively.
Tools
| Category | Technologies |
|---|---|
| ML & notebooks | Amazon SageMaker (Jupyter), Python |
| Orchestration | AWS Lambda, AWS Step Functions, Amazon EventBridge |
| Data & access | Amazon S3, Amazon RDS, AWS IAM, Amazon CloudWatch |
| Visualization | Power BI |
Results
The outcome is a fully automated, cloud-native ML pipeline: ingest and tier data, run cleaning and transformation steps serverlessly, train and surface predictions with proper RBAC—and deliver business-ready views through Power BI.
Screenshots
Diagrams below are edge-trimmed from your originals so only the architecture content is emphasized (margins and peripheral UI removed where present).
High-level architecture (medallion + event-driven flow)
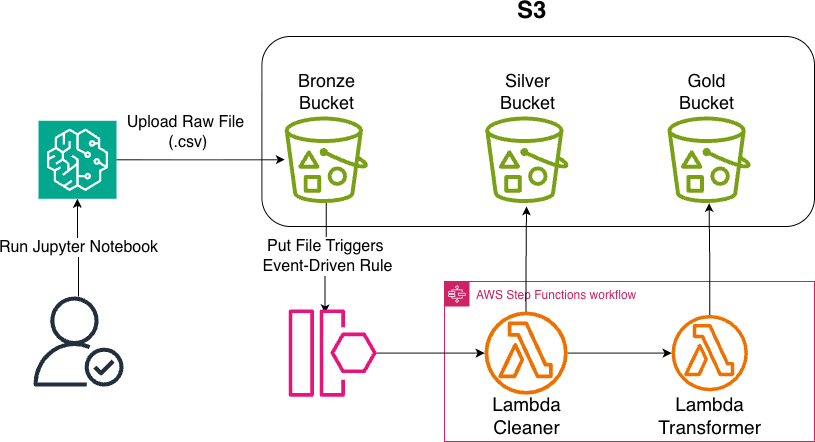
Step Functions workflow (start to end)